 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025



Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
Generating Physically Stable and Buildable LEGO Designs from Text
May 08, 2025


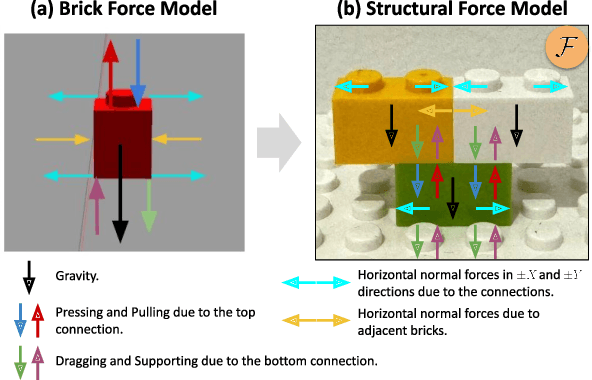
We introduce LegoGPT, the first approach for generating physically stable LEGO brick models from text prompts. To achieve this, we construct a large-scale, physically stable dataset of LEGO designs, along with their associated captions, and train an autoregressive large language model to predict the next brick to add via next-token prediction. To improve the stability of the resulting designs, we employ an efficient validity check and physics-aware rollback during autoregressive inference, which prunes infeasible token predictions using physics laws and assembly constraints. Our experiments show that LegoGPT produces stable, diverse, and aesthetically pleasing LEGO designs that align closely with the input text prompts. We also develop a text-based LEGO texturing method to generate colored and textured designs. We show that our designs can be assembled manually by humans and automatically by robotic arms. We also release our new dataset, StableText2Lego, containing over 47,000 LEGO structures of over 28,000 unique 3D objects accompanied by detailed captions, along with our code and models at the project website: https://avalovelace1.github.io/LegoGPT/.
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles
Jan 16, 2021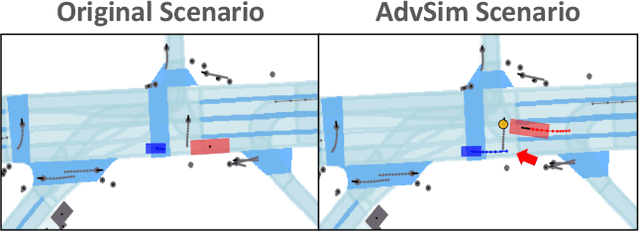
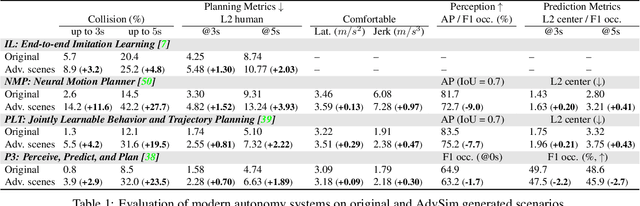

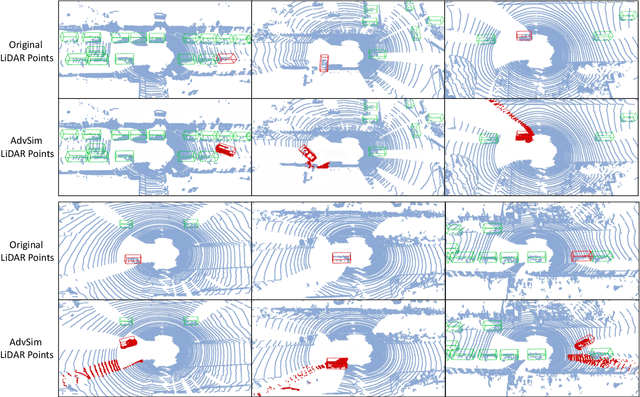
As self-driving systems become better, simulating scenarios where the autonomy stack is likely to fail becomes of key importance. Traditionally, those scenarios are generated for a few scenes with respect to the planning module that takes ground-truth actor states as input. This does not scale and cannot identify all possible autonomy failures, such as perception failures due to occlusion. In this paper, we propose AdvSim, an adversarial framework to generate safety-critical scenarios for any LiDAR-based autonomy system. Given an initial traffic scenario, AdvSim modifies the actors' trajectories in a physically plausible manner and updates the LiDAR sensor data to create realistic observations of the perturbed world. Importantly, by simulating directly from sensor data, we obtain adversarial scenarios that are safety-critical for the full autonomy stack. Our experiments show that our approach is general and can identify thousands of semantically meaningful safety-critical scenarios for a wide range of modern self-driving systems. Furthermore, we show that the robustness and safety of these autonomy systems can be further improved by training them with scenarios generated by AdvSim.